git vs. Dropbox
from a researcher's perspective
31 Jan 2016
Many researchers write a lot of code. And research projects last a long time, with new ideas and iterations along the way. We try different strategies, we change things, sometimes we change them back. Occasionally we wonder why things changed when we’re pretty sure we hadn’t changed anything.
We all have strategies to deal with this, and they work well enough to let us write our papers. You might have a folder with files labelled _v1, _v2, …, _vN, _vfinal. Or you might use Dropbox to automatically generate and catalog those versions for you.
I’ve written papers using both of those strategies, but I hope I won’t have to again. Managing the versions of a project can be easier, less stressful, and less error-prone.
These are some of the reasons why I think everyone working on code with others should use git.
1. In git you have versions of the project, not just versions of each file.
Suppose you try something that changes many files, but then decide you don’t like it and want to roll back to how you had it before. In Dropbox, you find each file and restore the previous version. Did you get them all? Are you sure they’re all restored to the versions that match each other? With git, I double click on a version and poof, the whole project is back to the way it was three weeks ago. Double click again, and instantly everything is restored back to the present. (You can also restore individual files, of course.)
2. “Why did this number change?”
A question that’s been the cause of much anxiety in my life, and perhaps yours? “This coefficient was 0.98 three weeks ago. Why is it 0.96 now?” asked the PI. How would you go about tracking down the likely causes of the change if you’ve versioned everything in Dropbox? In git, I’d very easily generate a ‘diff’ comparing the code base from three weeks ago to the code from today, and look over those changes to see what affected the result.
3. Each version is deliberately tied to a meaningful change (and message describing that change), not just an iterated number.
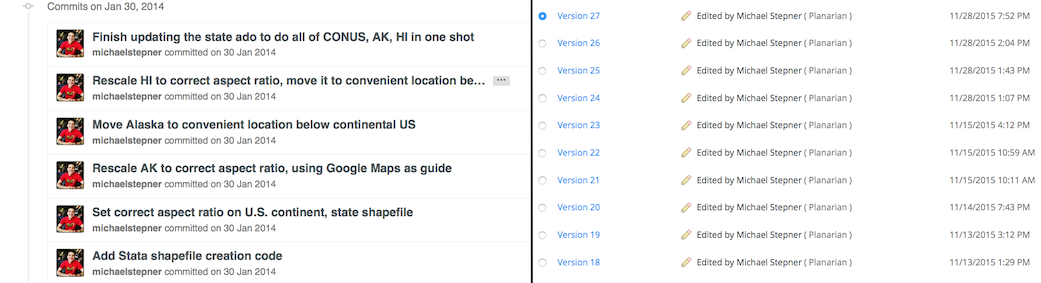
If you’re working on a file all day, you’re probably going to save it a bunch of times. In Dropbox, that’s Version 18, 19, 20, 21, 22, 23, 24, etc. In git, when you’re done with some meaningful chunk of work, you ‘commit’ that change with a message. It’s clear to your collaborators (or yourself two weeks later) what you did, when and why.
4. Tinkering is easy, undisruptive, and risk-free.
Let’s say you have a great idea for improving the project: maybe you’re going to edit & reorganize a bunch of code files. But while you’re working on it, the half-finished version is going to break everything for everyone. In Dropbox, you could turn off syncing… but what if you want to spread your work over a few days? While your collaborators work, you can’t keep up with their changes over those days. You could copy the code and edit in a separate folder, but what if other people are changing the main code while you’re at it? How are you going to combine your changes with theirs and be sure you’ve done it right?
In git, you’d create a branch and start tinkering. Try anything: it’s easy to scrap all your changes (see point 1). Others can see what you’re working on, but you’re not disrupting their work. When your work is done and ready for primetime, you can see what’s changed since you branched off and merge your changes back into the main code systematically: automatically, or with git holding your hand through any conflicting changes.
A different common scenario: somebody else wrote some code that you need to change, but you want to check with them that your changes look good to their eyes. In git, I’d make the change, commit it, and ask them to look over the ‘diff’ to make sure it looks right to them. In Dropbox, you might make a copy of the code file (_v2?) and ask them to compare the two. (What if the filename is referred to by other code? Update it to refer to v2? Annoying and error prone.) It’s possible, but much less straightforward.
After working with git, Dropbox stresses me out.
When I collaborate over Dropbox, I feel nervous about making changes to the code. Especially if the changes I’m considering affect many files or delve into code I didn’t originally write, I’m fearful of the unintended consequences. I even get worried coming back to my own code if I haven’t touched it for a while: what’s changed since I last used it? Anything I need to be aware of before I edit it?
git is liberating! Take chances, make mistakes, get messy. The research process is always messy, and a good version control system will help you organize it.

Okay, so where do I start?
There’s a small learning curve, but it’s not nearly as hard as Googling “git tutorials” makes it seem. You don’t need to be a command line guru or a software engineer, I promise. You don’t even need to open the command line!
I led a Git for Researchers workshop in the MIT Economics department in January 2016. I’m planning to adapt the workshop materials into a series of blog posts: you just read Part 1. The next post, Part 2, will introduce how git works. Part 3 in the series will show you how to use git.
They’ll be posted here when they’re ready!
Comments? Questions? Get in touch via Twitter or Email.
Or go back to the main blog page.
All writing on my blog is under a Creative Commons Attribution 4.0 International License.